

Ad Turing Test Results // BrXnd Dispatch vol. 022
Sharing the results of the first ad Turing test. Plus announcing #2 in SF in the fall!

You’re getting this email as a subscriber to the BrXnd Dispatch, a (roughly) bi-weekly email at the intersection of brands and AI. We are officially coming to San Francisco this Fall for the BrXnd Marketing X AI Conference. Right now, we’re giving all sponsors who sign on before we lock down date+venue 20% off. If you’re interested, please be in touch.
Last week I wrote a bit about the Ad Turing Test we ran as part of the first BrXnd Marketing X AI Conference. I also promised that I would be back with the results. So let’s get to it.
First, if you haven’t already taken the Test and want to see how you do telling human ads from ones created with AI, go ahead and do it now before you read on. What follows are spoilers.
Ok, let’s dive in. As I outlined last week, the first Ad Turing Test rules were reasonably straightforward: humans could make ads however they wanted, and AI teams could only generate ads using models. In addition, all teams were given the same brief to work with, along with Volt brand assets. (The Volt brand was designed by the fine folks at Otherward.)

Teams
We recruited ten teams, seven of them being students representing humanity and the other three being ad professionals representing what’s possible with AI. You can find the complete list of teams and ads on the Ad Turing Test site. The AI teams were:
When we started recruiting teams back in January for the Test, there were a lot of questions about how the AI teams would approach the problem. At that time, the biggest challenge was dealing with the logo (the rules prevented teams from doing manual post-processing). Within a month, ControlNet, a model that allowed you to detect the outlines of shapes and merge them with other images, was released. A few weeks after that, GPT4 came out. While I was unsure exactly how the AI teams would approach the problem, in the end, most had GPT code a layout.
Ads
Below are all ten ads. Ads 1, 3, and 6 came from the AI teams, and the rest came from the humans.

Ted Florea and Keith Butters of Team Ancient made a video of their ad-making machine:
Results
As for the results, there are three ways to look at them:
Jury: We recruited a jury of super-experienced industry folks to see if they could spot the difference between the human and ai-generated ads.
Public: At the conference, we had everyone take the Test and have since released it publicly. Over the last two weeks, almost 600 people completed the Test (evaluated all ten ads).
System1: Finally, the folks at System1 Group were kind enough to run creative testing on all the ads.
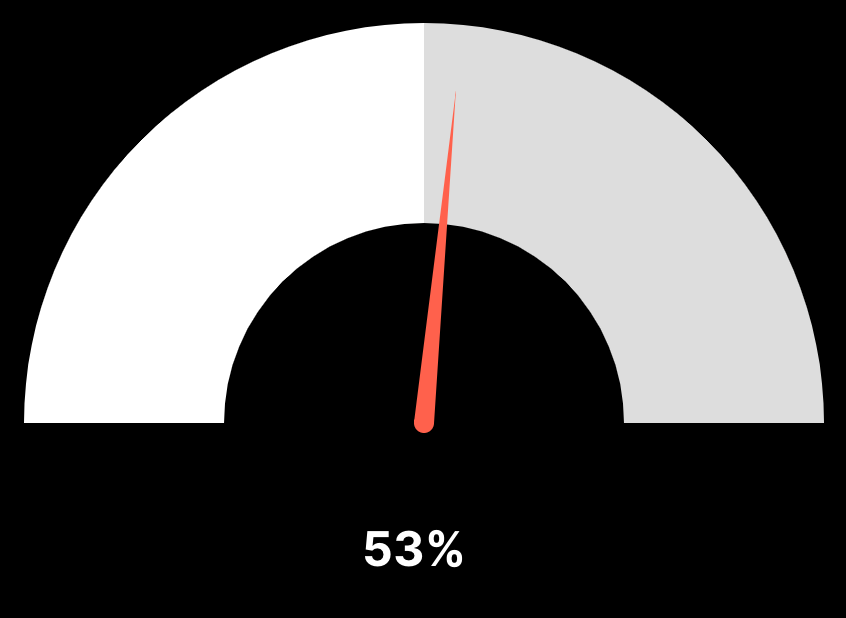
The jury and the public weren’t far off, with the ad pros coming in at 56%, and the public currently running at 53%. That means that 53% of the human/AI guesses were correct. This is pretty close to coin-flip territory and says a lot about people’s ability to tell the difference between human and AI-generated ads.
Of course, these were student ads, so we aren’t necessarily comparing the output of AI versus the most seasoned advertising professionals. But this is also where System1 Group’s creative testing results become particularly interesting. As a group, the majority of the ads performed above System1 Group’s US print ad benchmark. This means that, on average, the ads produced by humans and AI were above most of what System1 sees (and they see a lot).
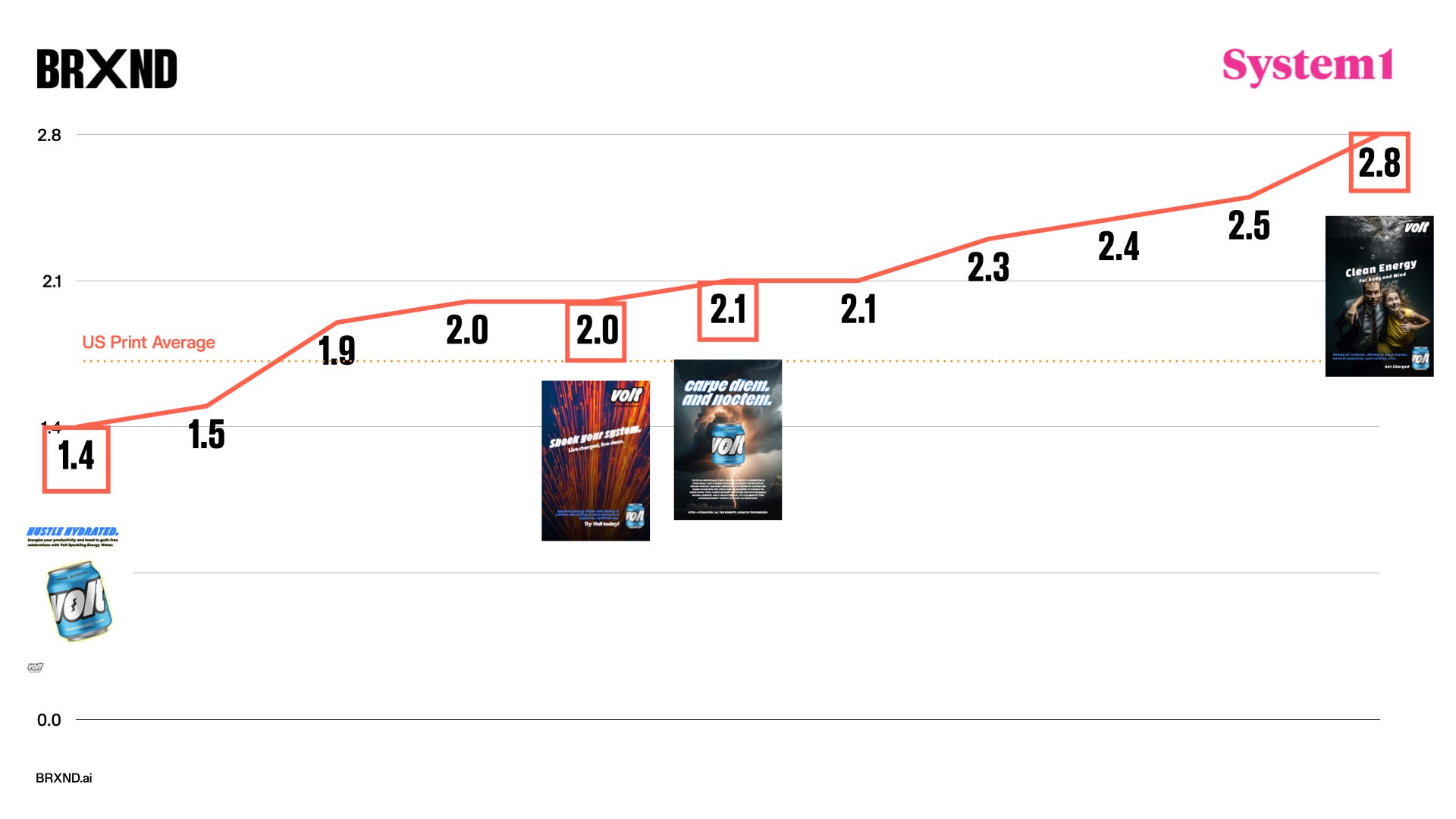
One other interesting note, if you’re paying attention, is that there are 11 ads in that chart. We had to disqualify a second ad from the Ancient team because it was hand-constructed (all AI-generated elements, but they put the final cut together in Photoshop). Ted and Keith were totally transparent about this and asked if we could still test it out of curiosity. Interestingly, that ad scored the highest, well above the rest and far above the US Print Average.
Conclusions
What do we make of all this? Like a lot of stuff having to do with AI, I’m not really sure. The idea of the Test was to have some fun and set a benchmark for where this technology is today as applied to advertising. I think we can safely say that a) it’s in pretty good shape, and b) it will only get better. Also, in the real world, folks using AI don’t have the sort of restrictions around human/AI collaboration that we put on the AI teams. There aren’t rules like the one we set, and when put in the hands of professionals, you can clearly make creative work that tests well. In the end, this technology clearly has a place in the industry.
Also, because it was so fun and interesting, we will do another fall test at the San Francisco event. We want to raise the ante and include a prize pool for humans and AI winners. We are also looking for a sponsor who might want to a) help fund the Test and b) offer their logo and a brief to work off. So if you’d like to participate as a human or AI team, please be in touch, and if you’re interested in being that sponsor (or have a client that might be), definitely hit us up as well.
A huge, huge thanks to all the students and other participants. This was great fun, and I’m excited to see what the future holds.
Further Reading
Lots of good stuff was written about the Test. Here’s a small sampling:
That’s it. Thanks for reading. If you have a friend who might enjoy this, please send it along to them. Also, if you’re interested in helping us put on San Francisco as a sponsor, please be in touch.
Thanks,
Noah