

Building a Shopping Bot // BrXnd Dispatch vol. 022
On the trials and tribulations of building a micromobility vehicle shopping bot.

You’re getting this email as a subscriber to the BrXnd Dispatch, a (roughly) bi-weekly email at the intersection of brands and AI. We are officially coming to San Francisco this Fall for the BrXnd Marketing X AI Conference. Right now, we’re giving all sponsors who sign on before we lock down date+venue 20% off. If you’re interested, please be in touch.
My ongoing goal with BrXnd is to explore the intersection of marketing and AI through experimentation rather than pontification. There are plenty of people out there with lots of opinions about AI that might be right or wrong, and I think I am best suited to focus on the realities of using and building these amazing new tools.
To that end, I’m excited to share a new thing I’ve been working on: my first shopping assistant for the number one micromobility (ebikes, scooters, etc.) review site, Ride Review.
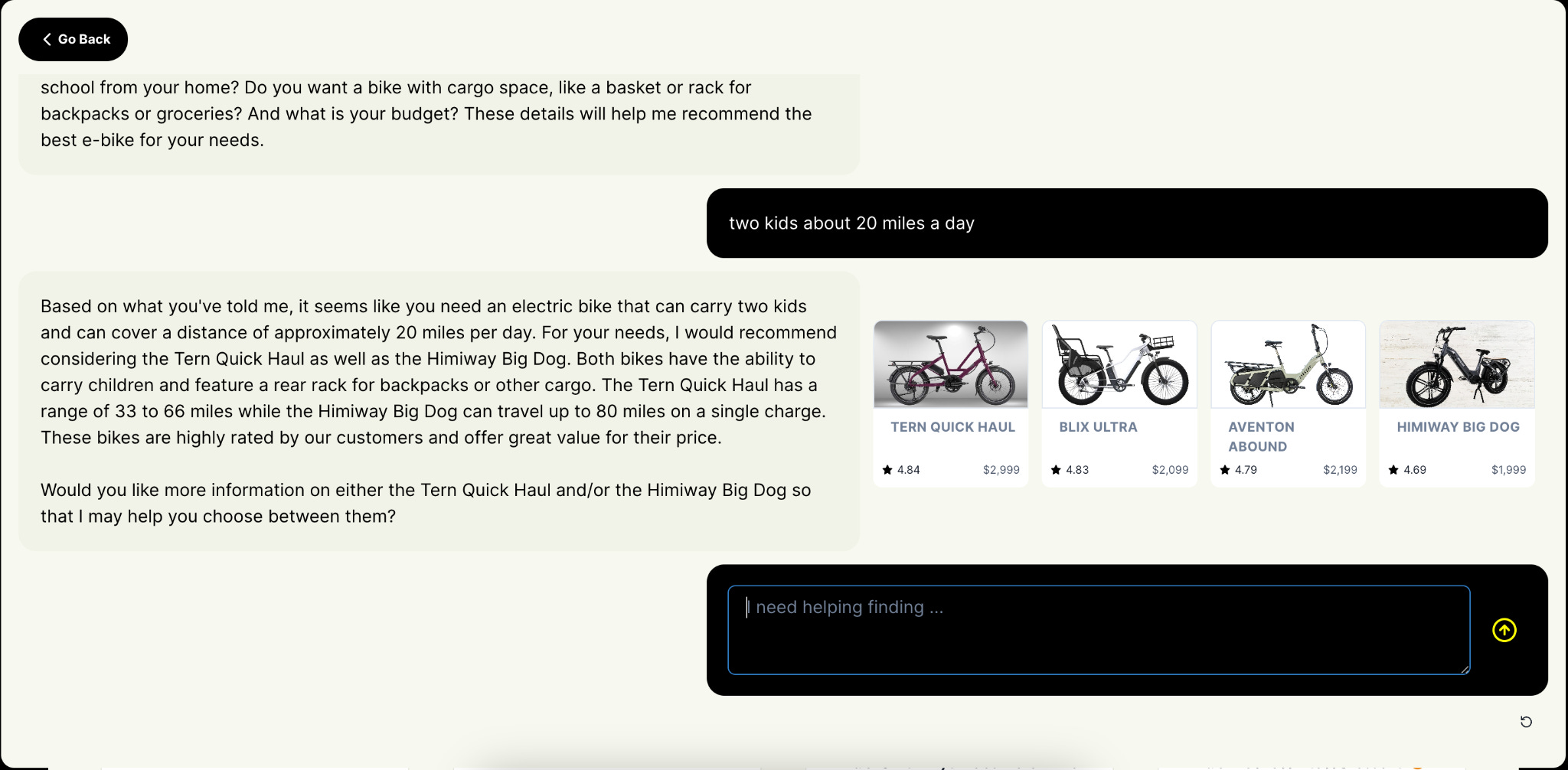
The bot is called Ride, and we launched it this morning. I thought it would be a reasonably straightforward problem, but for a bunch of reasons I will explain, it turned out to be much more complicated. Of course, there’s lots more work to do, but I’m really happy with where it landed.
The basic idea is pretty simple: at Ride Review, we have thousands of reviews of micromobility vehicles and related products. But these are big purchases, and thus many people want a bit more guidance in choosing the right one. While faceted search is cool and useful, we thought it would be better to build our own assistant.
My first thought on how to crack the problem was to reshape the vehicle data so that I could generate embeddings and do vector search over the whole thing. In this approach, I utilized the AI’s ability to understand the context of any data and then a vector database’s ability to find the nearest neighbors based on the embeddings. As people answered questions, I would build a set of preferences that looked like the vehicle data I had generated an embedding with. If all that sounds complicated, it was! The basic concept is that I came up with a taxonomy I could use to describe both vehicles and people’s preferences for vehicles. Then I would fill in the preferences taxonomy and continually find its nearest matches.
The problem with that approach is that similarity isn’t good enough for this kind of problem. Suppose you’re building simple search (like I do with the BrXnd Marketing AI Landscape where you can find products by use case) or a bot that needs to access a bunch of written material. In those cases, embeddings are great: you can look up the most contextual text for what has been inputted by the user and return it. But when you’re looking for a micromobility vehicle to buy, you don’t just want similarity, you also want to filter. What I mean is it’s not good enough to find the closest matches to “ebike that can go above 30 mph” if those matches aren’t ebikes. Ebike and >30mph are filters—and while it’s possible to do that with a vector DB, it can get pretty complicated.
The other big problem I ran into was a tradeoff decision: either we asked the AI to return data in multiple formats, or we made multiple calls. Because I needed it both to respond to the user and interpret their answer into a preferences taxonomy, I either needed to try to find a prompt to get it to return both at once (consistently), or I needed to make multiple calls, which would slow down the app considerably. This kind of production problem brings AI out of the theoretical and into the practical. I did some tests and couldn’t really crack the two-format thing, so I was stuck with two calls instead. I probably could have done it if we were willing to spend the money on the GPT4 API, but the difference in price between 3.5 and 4 is 30x!
After much playing and tinkering, I finally cracked it by figuring out a way to get it to return a minimal representation of the user’s vehicle preferences (fast!) that I could then use to search our database and return results. Those results were then passed to the bot, which would include them in its response.
In the end, the whole process feels pretty seamless and quick:

A few things that struck me through the build:
I really do think this kind of research-heavy shopping process lends itself well to the chat experience. Salespeople exist for a reason, and these bots can make a pretty amazing approximation of a very experienced salesperson at guiding you through the types of questions you should be asking for a multi-hundred or multi-thousand dollar purchase.
There is a lot of code in here. Actually making these things work in production isn’t just a matter of adding some AI and flipping the switch. There is a lot of translation between the data returned from the AI and what you need to find the right results. I will continue to refine my approach here, but it is pretty complicated and not totally clear where to simplify/abstract.
Outside the code, the process of getting the personality and quirks ironed out feels like a very new kind of thing. I kept describing it as “massaging the prompt,” and that’s really what it felt like. I was trying to smooth the edges of the bot by adding minor updates and addition to the various prompts that are used with lots of conditional logic.
If you’re in the market for an ebike, scooter, or other micromobility vehicle, you can go give it a try on the Ride Review site. Let me know what you think of the bot, and if you want to try your hand at building one, I put up a very basic repo on Github. Also, I spend a bit of time each month working with folks on these sorts of projects, so if you’re interested, feel free to be in touch.
That’s it. Thanks for reading. If you have a friend who might enjoy this, please send it along to them. Also, if you’re interested in helping us put on San Francisco as a sponsor, please be in touch.
Thanks,
Noah
PS - If you want to continue the conversation and chat with other folks interested in this intersection between marketing and AI, join us on Discord.
You should check out LlamaIndex they have pretty good stackable search so you can do something like filter by category or keyword and then rank by similarly. Hybrid search is consistently outperforming keyword or vector only methods. https://gpt-index.readthedocs.io/en/latest/index.html also Anthropics Claude model I find has similar or better performance to GPT4 at lower cost and better speed.