

So Easy a 7-year-old Could Do It // BRXND Dispatch vol. 061
Trying to get AI to solve a first-grade word search

You’re getting this email as a subscriber to the BRXND Dispatch, a (roughly) weekly email at the intersection of brands and AI. The next edition of the BRXND Marketing X AI Conference will be in LA on 2/6. If you’re interested in attending, early bird tickets are on sale UNTIL 12/10 for 15% off. If you’re interested in sponsoring, we’ve got a form for that as well. (Oh, and if you want to speak or know someone who should, let me know that too.)
I’ve got something a little different today, but I think it’s a good story about what AI is and isn’t good at and why.
The other day, on my basketball group chat, my friend Ricky shared a word search his son had gotten at school (this is all shared with his permission, of course—thanks, Ricky!). He thought it would be easy enough to give to ChatGPT and have it solve it, but this assumption turned out to be wrong. It was “giving incredibly confident and wrong answers,” he explained. “Go to row 8 and column 12 type precision and just being wrong over and over.”
Ricky concluded that he “Needed assistance and received none. "Unable to resist an AI challenge, I asked if he would share the images to see where I could get with it. If you want to try it yourself, take the photos below and see where you get before reading on. The challenge is to see if you can get AI to solve the word search.


In many ways, this seems like a fairly easy problem for AI. After all, the word search was created for a seven-year-old, and surely frontier models can operate at a first-grade level. But Ricky knows what he’s doing, and it wasn’t giving him the answers he wanted, so I was curious if some other approaches could help solve the problem. My first thought was that if it couldn’t just process the answers from the image alone, the best approach would be to get it to rebuild the grid using code and then have it easily find the words in the now structured data. My initial ChatGPT 4o prompt was pretty simple: “Ignoring the circles, extract this word search into a table maintaining the spaces.” That … did not really work.

The alignment was way off, a problem that would keep repeating itself no matter what I tried. While the AI was very good at reading and mapping the letters, it had a massive amount of trouble dealing with the whitespace. I couldn’t help but wonder if its challenge with whitespace wasn’t related to its constant need to always answer questions. Just as you have to tell the model it's okay to say it doesn’t know something, was it incapable of leaving the whitespace because it believed it needed to fill things in? I doubt that’s the case, but it’s still fun to wonder. It’s much more likely this is just an issue with how the vision model interprets space.
Anyway, some more tries with ChatGPT didn’t lead anywhere, so I jumped over to Claude with the hope that being able to write and display JavaScript wouldn’t solve my problem. I gave Claude the same initial prompt, which gave me back Markdown …

That wasn’t the answer I needed. I tried a new approach, asking it to build a grid of letters and numbers and eventually asking for answers. The responses it gave were generally okay (“rescue” is pretty close to 7N, and “clue” is near 11L), but they were still not very aligned, and it failed to find any vertical or horizontal words.
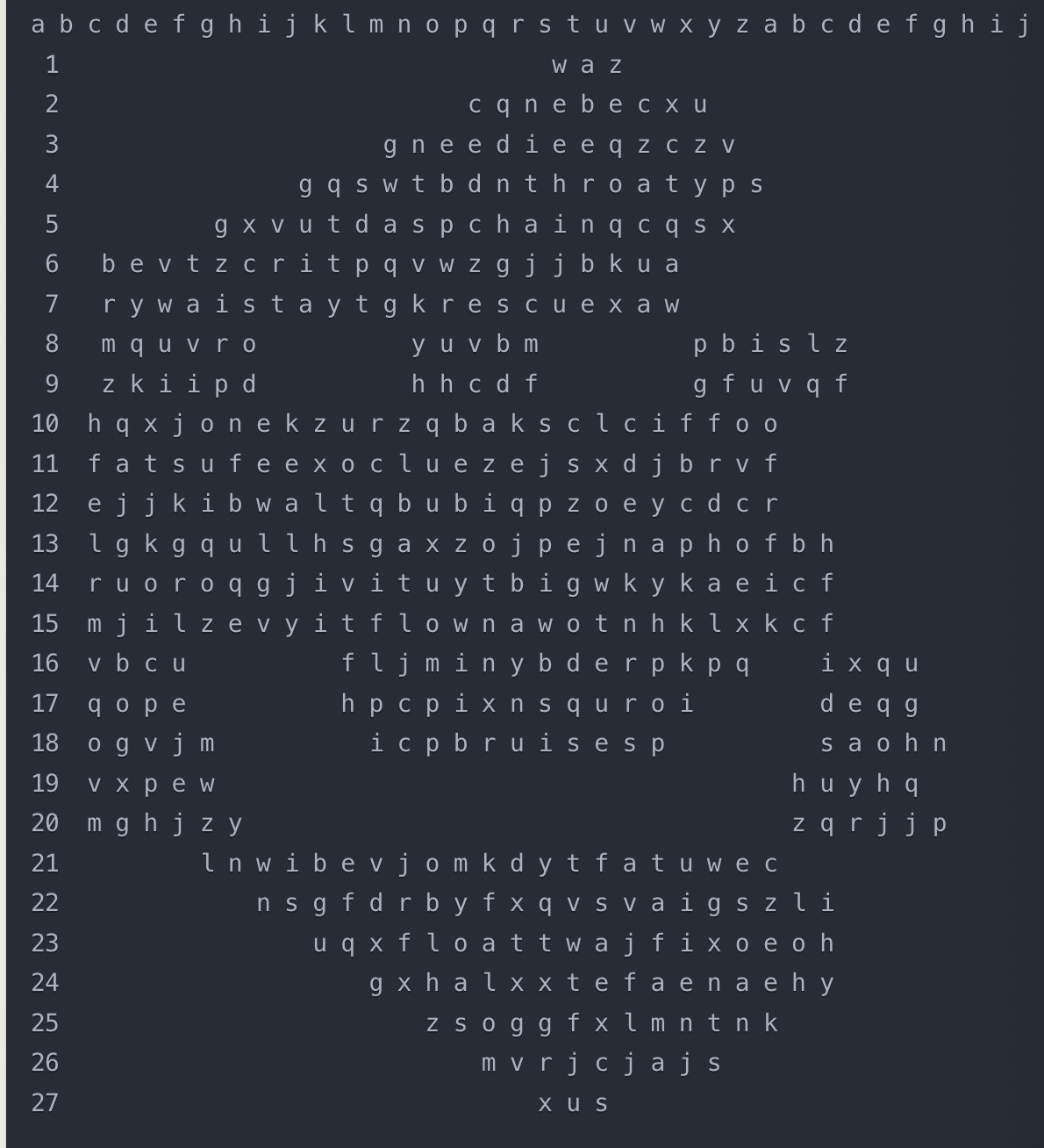
I concluded that Markdown was likely a dead end and would need some code. Claude Artifacts uses React, a javascript framework, to display output. So I started a new chat and took some of what I learned: “look at this image. it's a word search. i want to recreate it as a react component. i want you to ignore the circles. number the columns, letter the rows. make sure you stay true to the exact layout, to do that you should probably start by counting the row with the most letters and working off that as your grid. account for the shape (smiley face with eyes and mouth).”

Now we’re getting somewhere. I can see hints of the proper layout, but clearly, the whitespace is still messing up. When I looked at the code it had written, I started to see why:

You can see in the first row that it starts with three nulls, even though WAZ was centered in the original word search. I really wanted it to count and align everything, but no matter what I asked, I couldn’t get it to count the empty spaces correctly. Eventually, I told it to switch its approach: instead of counting the empty spaces, why doesn’t it just capture the letters in each row and then count the longest row and fill in whitespace evenly around each row until it reaches that length? (The prompt: “it's still not right. my suggestion is to only use null where you need internal spaces and then read nullls evenly around all rows to make it equal the maximum” and then “no, that's wrong. stop adding external nulls to griddata and add it programmatically when displaying, that will ensure it's evenly spaced.”)
We interrupt this newsletter to offer a word of thanks to our sponsors for BRXND LA 2025. Airtable is operations for the AI era. Getty Images is a preeminent global visual content creator and marketplace with a commercially-safe AI platform. A huge thanks for their support. If you’re interested in sponsoring BRXND LA 2025, please be in touch.

This was by far the closest I had gotten yet:

So I thought, “Here we are; I’ve solved it!” I gave Claude the word list and asked it to find the words. It confidently told me it had found nine of them …

It did not … I tried a bit more coaxing but eventually decided I wouldn’t get where I needed to. However, writing React code seemed like the most promising solution, so I switched to v0, a service from Vercel that was purpose-built to write React apps. I took everything I’d learned so far and flipped over to my third service. Along with the image, I asked it to “accurately display this word search as a grid with numbered columns and lettered rows and let the user highlight words vertically, horizontally, and diagonally” And I got this …

I did some more back and forth with v0 but couldn’t nail it. Strangely, though, I couldn’t see what was wrong in the code. When I looked at the grid and the way it was handling centering, it was doing exactly what I asked. It just wouldn’t display correctly.

Nothing seemed to let me show past Row O or Column 15. I eventually concluded that this was probably an issue with the small display window on the v0 site, so I grabbed the code and stuck it into a codebase I controlled to see how it displayed. Everything looked right!

In the end, I didn’t ask the AI to find the words, though I imagine it can now. If you want to try it yourself, I posted it as an experiment on the Alephic site.
Takeaways
So, what did I learn from this other than that I can easily waste two hours on a word search created for a seven-year-old?
The joy of AI experimentation: This wasn't just solving a puzzle—it became an exploration of how different AI tools tackle spatial reasoning. Each attempt revealed something new about these systems' thinking patterns. Try it yourself and see what you come up with. I also think there’s a general thing here with prompting puzzles that I want to explore some more.
Deceptive simplicity: What's easy for a 7-year-old isn't necessarily easy for AI. While the model had no trouble reading letters or finding patterns, it got weirdly stuck on spatial relationships and empty space. Understanding not just how these models process, but how they combine their functionality together (vision to text) is important to getting the most out of them.
Finding AI's edges is valuable: Sure, you can read docs and take courses, but nothing beats hands-on experimentation. This little project reinforced something I've been saying for a long time: it’s all about building intuition. Prompt engineering is less about memorizing techniques (though there are certainly a few worth knowing) and more about developing a feel for how these systems think and where they might get stuck.
The power of multiple approaches: Sometimes, the best solution involves a mix of tools and techniques. Moving from ChatGPT to Claude to v0 involved more than trying different services—it was about leveraging the strengths of each offering. It’s best to think of these different services as more than just models: they all have their own capabilities (ChatGPT with code interpreter, Claude with Artifacts, etc.) that make them fully functioning applications.
That’s it for now. Thanks for reading, subscribing, and supporting. As always, if you have questions or want to chat, please be in touch.
Thanks,
Noah