Hi everyone. Welcome to the BrXnd Dispatch: your bi-weekly dose of ideas at the intersection of brands and AI. I hope you enjoy it and, as always, send good stuff my way. Today’s post is a bit nerdier than usual, so please bear with me. It’s a super powerful GPT3 prompt that I have shared with a few friends to great effect. NYC spring 2023 Brand X AI conference planning is in full effect (targeting mid-May🤞🤞). If you are interested in speaking or sponsoring, please be in touch.
When I built the CollXb engine, the most striking thing was that good brands made better images. While at first that seems supremely obvious—of course, good brands produce better output—if you think about it a bit more, it’s not so clear that should be the case. Being a “good” brand, after all, is mostly subjective. Sure, we have lists like Interbrand’s Best Global Brands that purport to rank and value brands, but a big part of the methodology is the company's total value, meaning small but powerful brands don’t make the list.
A look at some of Interbrand’s top brands from 2022
“Some brands clearly overpower others,” Brier says. For example, almost anything involving Hermès tends to come across “more Hermès than the other brand,” unless the collab is with another high-power brand like McDonald’s or the Grateful Dead. Nike is an even more extreme example: “If you ask it to make a sneaker, whatever brand you choose, it’s very hard to keep a swoosh off of it.”
This isn’t just a matter of having mass presence. In some cases, the AI is able to recreate the brand aesthetic of more niche brands like The Hundreds or Ghostly, in ways that ring remarkably true, suggesting that such brands achieve “salience without scale,” as Brier puts it. (Obviously, AI’s digital “training” gives it a bias toward recognizing and re-creating “more internet-y brands,” he notes.) And there are other results that have surprised him—like how well Hot Topic’s brand aesthetic consistently comes through.
And so began a dive into trying to understand what the model understands about these brands. I have spent the last few months trying to get to the bottom of how it came to have an “intuition” for great brands.
Thanks for reading BrXnd! This newsletter is just getting started. If you’re interested in the intersection of brands and AI, please consider subscribing.
One of the techniques I’ve been experimenting with is to try to map brand space as seen by the model. To do that, I give Open AI a bit of text, whether it’s the name of a brand or an attribute, and get back a series of numerical values. This array of 1,536 digits represents a point in multi-dimensional space that the model associates with that text. If all that sounds a bit hard to comprehend, here’s a simpler explanation from my post introducing my marketing AI landscape:
To understand what this means, let’s imagine it works in two-dimensional space (it doesn’t—it is working with many, many times that number of dimensions). If I tell it that one use case of WellSaid, a text-to-speech product, is to create a podcast from blog posts, it will give me a set of dimensions that locate that “idea” in vector space. Again, in our two-dimensional toy version, let’s pretend it looks something like this:
Each dot indicates a different company/use case. They are situated based on the vector values assigned. When you search for something, it gets its own location in space, and that can be compared to other clusters to show relative similarity and closest neighbors. This is a toy because the real version happens in 1500+ dimensional space, not two, but hopefully, it makes it a lot more comprehensible. It’s an incredibly powerful tool, and it works because of all the hard work that already went into training the model off the huge corpus Open AI works with.
So that’s the basic approach, but a series of thousands of numbers isn’t particularly useful to look at or imagine. None of us has the brainpower to picture 1500+ dimensional space, but luckily there are some techniques for bringing the data back down to two and three dimensions using a method called principal component analysis (PCA). The basic idea is that you do a bunch of math that I don’t understand (but thankfully, there are tools to help me), and it gives you back a set of vectors that represent the most variance in output across your dataset. (I really hope I’m explaining this right, if not, feel free to correct me in the comments.) For instance, when I am trying to map brands, I give Open AI something like “Brand: Nike” and “Brand: Red Bull,” so some part of the vectors almost certainly represents “Brand.” Because all the brands will have that same set of outputs, those vectors be thrown out. In other words, we want to know what makes them different, not what makes them the same.
PCA is not selecting some characteristics and discarding the others. Instead, it constructs some new characteristics that turn out to summarize our list of wines well. Of course, these new characteristics are constructed using the old ones; for example, a new characteristic might be computed as wine age minus wine acidity level or some other combination (we call them linear combinations).
In fact, PCA finds the best possible characteristics, the ones that summarize the list of wines as well as only possible (among all conceivable linear combinations). This is why it is so useful.
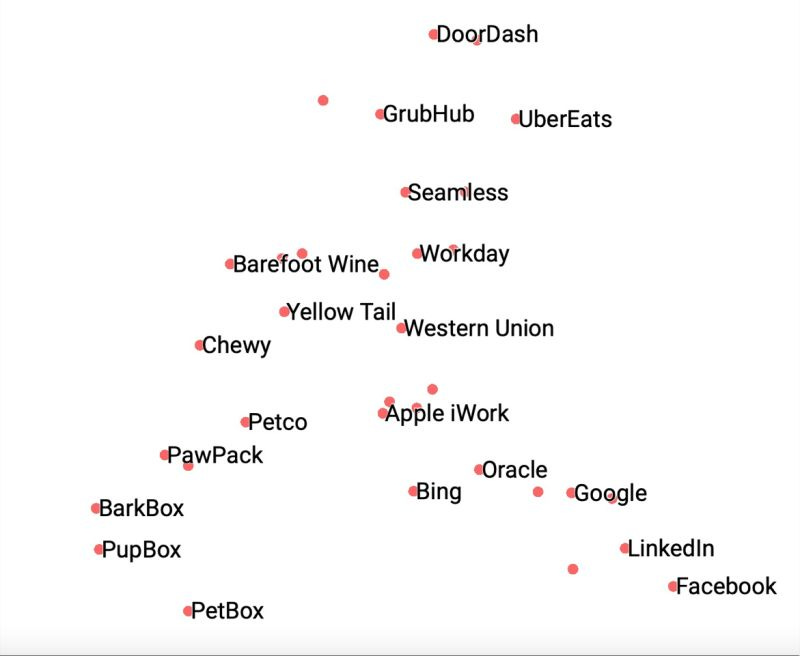
While I’m just at the beginning, it’s interesting to see just what this thing can do. Because it has a general sense of concepts from its gigantic corpus, it can group brands in meaningful ways without any other inputs. The image below is a two-dimensional analysis (I did a 3d one as well) of a bunch of brands that various friends asked me to include (hence the random assortment). What’s surprising about the image is how unsurprising it is. The model seems to have an intuitive understanding of categories when given nothing more than the brand’s name and some indicator that it’s a brand. (I do that so when I ask for Apple, for instance, I get the technology company instead of the fruit.) Since it seems basically correct, it also raises other interesting questions, like why has it grouped Western Union as the closest non-wine brand to Yellow Tail? Or what puts Google closer to consumer brands than Facebook?
2d clustering of brands straight from OpenAI embeddings
This is just the beginning, and lately, I’ve been playing with placing brand attributes in the mix to understand proximity. For example, after seeing the above image, my friend Dave Greenfield (who has also been writing about AI recently) shared a fun radar chart using some of the same ideas:
An attempt to visualize associations between brands and key attributes from Dave Greenfield
All this is just the beginning, but because so much of what makes brands work is the strength of the associations they build, it feels like this technology offers real promise for answering some previously tricky—or at least very expensive to answer—questions.
New BrXndscape Companies
New companies listed on BrXndscape, a landscape of marketing AI companies (writeup in case you missed it). If I missed anything, feel free to reply or add a company. (The companies are hand-picked, but the descriptions are AI-generated—part of an automated pipeline that grabs pricing, features, and use cases from each company’s website and one of many experiments I’ve got running at the moment.)
[Advertising Generation] Pencil: Pencil provides e-commerce brands and agencies with ad creatives predicted to win with AI, editing capabilities with free stock music, images, and video, as well as insights into ad performance with sharing, commenting, and approvals and industry benchmarks.
[Social Content Generation] Ocoya: Ocoya is a free AI content automation tool for creating and posting engaging social media content such as posts, captions, blogs, and hashtags.
[LLM App Development] Dust: Built on years of experience working with large language models. With one goal, help accelerate their deployment.
[Text-to-Speech] Altered: Altered Studio’s unique technology allows users to create compelling voice-driven performances from anywhere, with a wide range of voices and fine-grained accent control. It offers features such as Speech-to-Speech technology, Batch Mode, Transcribe It, and Add Voice-Over.
[Image Generation] Monster API: Monster API provides a dashboard to view billing and usage information, create API keys, access documentation, and receive 24/7 support. It also offers three subscription plans with credits ranging from 2,500 to 50,000 and allows for image generations with 50 sampling steps and a resolution of 512x512.
[Large Language Models] ALEPH ALPHA: ALEPH ALPHA offers revolutionary interaction capabilities with unstructured data and information for your organization’s growth. It is a conversational module built on our base AI model, “Luminous.” Plug-and-play, your data is safe, personalize your assistant, no more language barriers, and digital inclusion.
Thanks for reading. If you want to continue the conversation, feel free to reply, comment, or join us on Discord. Also, please share this email with others you think would find it interesting.
— Noah
Thanks for reading BrXnd! This newsletter is just getting started. If you’re interested in the intersection of brands and AI, please consider subscribing.