

Building with AI (+ 2024 Tickets on Sale!) // BrXnd Dispatch vol. 37
More making with AI + BrXnd NYC tickets on sale!

You’re getting this email as a subscriber to the BrXnd Dispatch, a (roughly) weekly email at the intersection of brands and AI. 2024 conference planning is now in full swing. I’m looking for sponsors and speakers (including cool demos!).
Before we dive in, I’ve got some good news for those asking about tickets to the NYC conference. I have about 30 tickets available at $650. There is a good chance I will release some more, but given the size of the venue (225 fire max, including staff), I have to be pretty careful. If you want to ensure you have a spot on May 8, 2024, get your ticket now.
Alright, onto the newsletter. In the last edition, I wrote a bit about the recommendations site I’ve been working on for Why is this interesting? WITI Recommends pulls out thousands of product recommendations from millions of words written for the newsletter over the five years of its existence. I’m happy to have launched it and have a few interesting AI-related tidbits to share.
As a quick refresher, I took the 1200+ posts from nearly five years of the newsletter and ran them through GPT-4 to extract all the product recommendations. From there, I set up a pipeline to scrape, extract, categorize, and do a few other things to make the site work. Again, what I think is most interesting about this is that it’s only really possible because AI exists. Sure, I could have manually done all this work or hired someone to do it, but that wouldn’t ever really happen.
I thought it might be interesting to go a level deeper and examine the different spots in the system where I used AI. Last time, I just touched the surface and shared the prompt I used to extract products from posts, but there’s AI all over the rest of the pipeline as well. The point of sharing this isn’t that any of you necessarily want to do exactly this, but I generally find that hearing how other people are utilizing this stuff helps to open the aperture on what’s possible, and typically, that’s the kind of stuff I like to do around here.
To start, here’s the full process a post goes through when it comes into the system (whether it’s a new one or an old one):
Extract Products
I covered this in detail already, so I’ll skip it.
Extract Author
While Colin and I wrote many of the posts, many are labeled “Guest Contributor,” so I ran the post through GPT-3.5 to grab the author. (As a rule, I use 3.5 when it’s a pretty simple task like this because it’s cheaper and faster.)
If the author isn’t yet in the system, I also do two other things:
Write Bio: I have GPT-4 extract a bio for them. Our posts mostly have short bios, so it’s about getting what’s already been written. I use a system prompt with instructions like “The bio should be concise, directly stating the essence of the contributor without elaborate details or specific post mentions. Focus on a clear, brief explanation that immediately conveys what the contributor is about to the reader. Use plain language to ensure accessibility and understanding at a glance.” and ask for everything to be returned as JSON. As I mentioned last time, the new response_format option in the API has been a fantastic time saver because it gives me back answers in a super easy-to-use format in code.
Grab author image: from there, I go out and grab a photo for them. To do that, I use AI again, this time to write a search query. Getting pictures of people, particularly with common names, can be challenging. And while this technique isn’t foolproof, it probably gets about 90% correct. I have it write a search query (“You will be given a name and bio for an individual. Convert this to a search term to ensure I get the right image for this person when I search Google Images.”), and then run it using SerpAPI (which is a fantastic tool that lets you programmatically access search results, including Google Images).
A big thank you to our first 2024 sponsors: Brandguard is the world’s #1 AI-powered brand governance platform, Focaldata is combining LLMs with qualitative research in fascinating ways, and Redscout is a strategy and design consultancy that partners with founders, CEOs, and CMOs at moments of inflection for their organizations. If you’re interested in sponsoring the 2024 event, please be in touch.

Extract Best URL
This is one of those things where AI is a game-changer. When a product comes in, some have URLs, and some don’t. For those with URLs, we would prefer the Amazon link if possible (for affiliate reasons), and for those without, we just need the best product link. Here, again, I turn to a combination of AI and SerpAPI. I get the search results for the product back and then give them to GPT-3.5 to get back the best link for that product:
You will be given the name of a product as well as a description and a set of results for that product on Google. Your job is to return the link that best represents a product page for that product using the following JSON format. It must be the exact same product. If you are not sure it is the exact same product return null. JSON format: {"url": string|null}(That last bit is another pro tip: giving the AI an out when it doesn’t know or find an exact match is a great way to avoid hallucinations.)
Extract Specs
I also went over this step last week, but the basics are that I scrape the product page and use AI to turn it into structured data that I can store in the DB.
Grab Images
Again, this is where AI turns a very hard problem into an easy one at about a 90% accuracy rate. Figuring out a hero image on a page isn’t easy: they’re not always labeled the same or in the same place. So, what I do is ask the AI for help. I give it a list of all the images (with a bit of HTML around them as context) and have it come back with its best guess for the hero image. Is it perfect? No, sometimes it chooses the wrong one. Is it right way more often than it’s wrong? Yup. Is that better than me doing it by hand? Most definitely.
Generate Embeddings
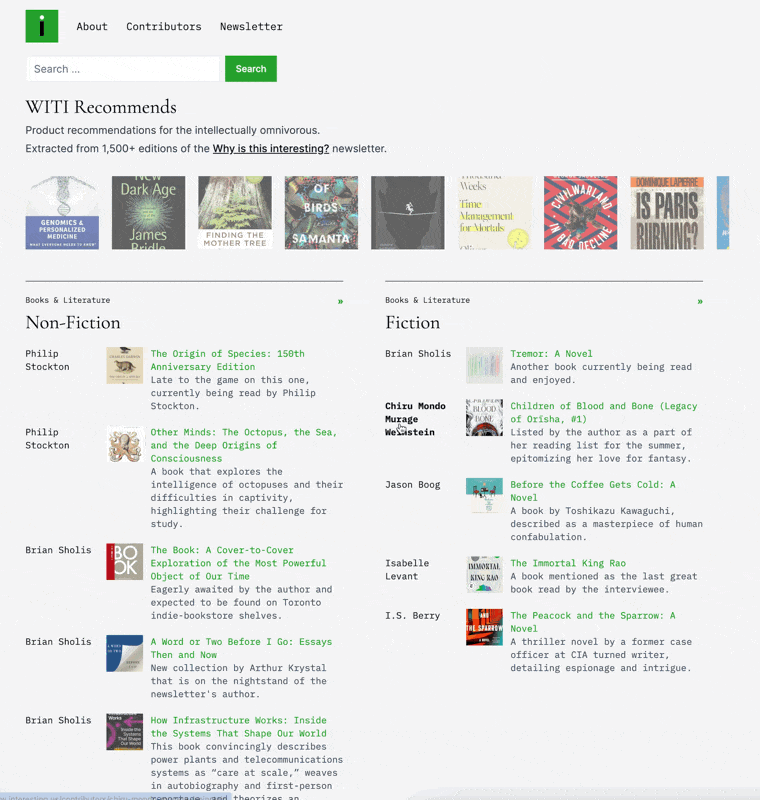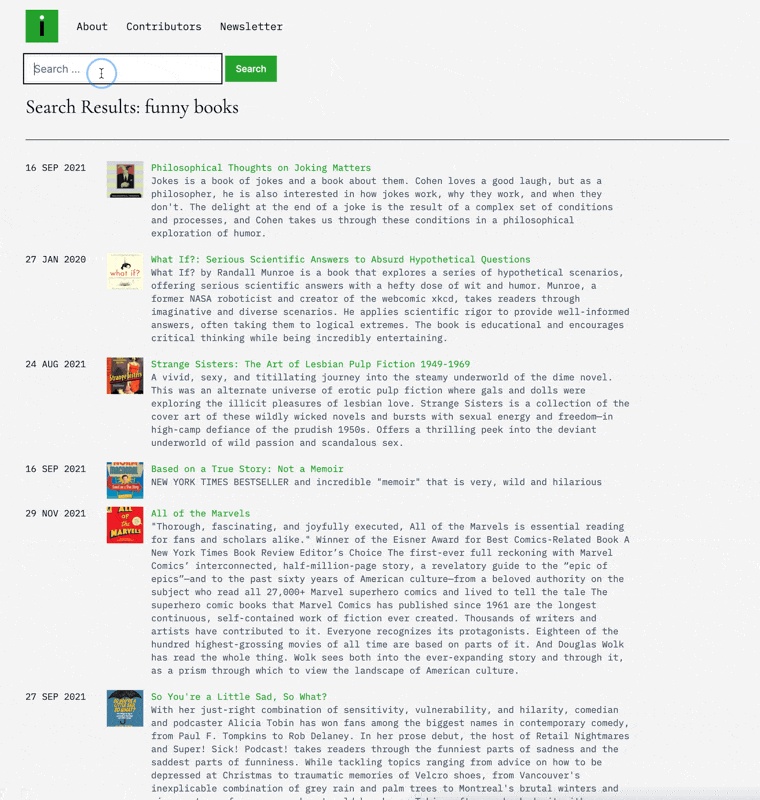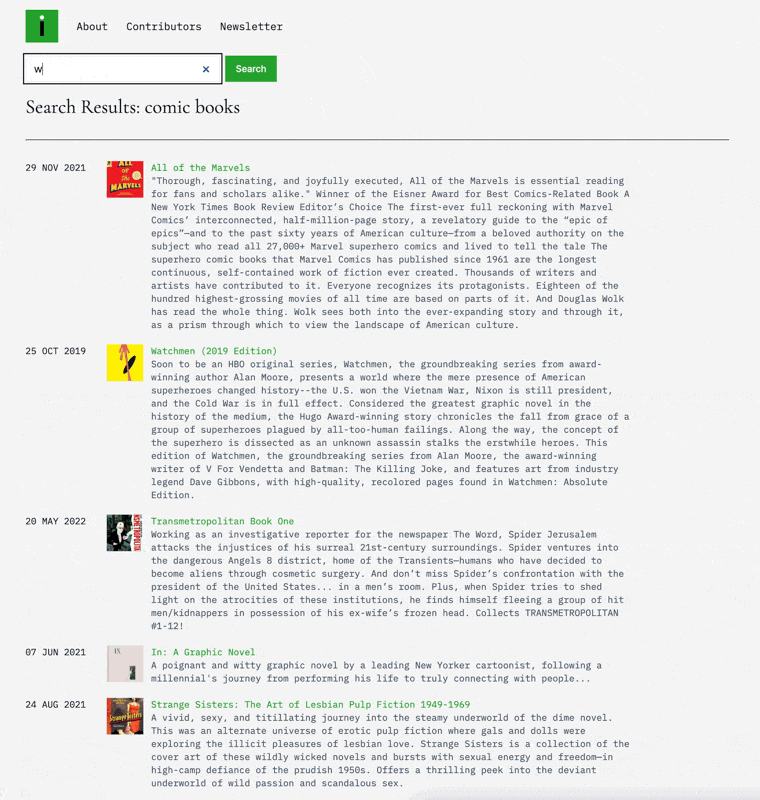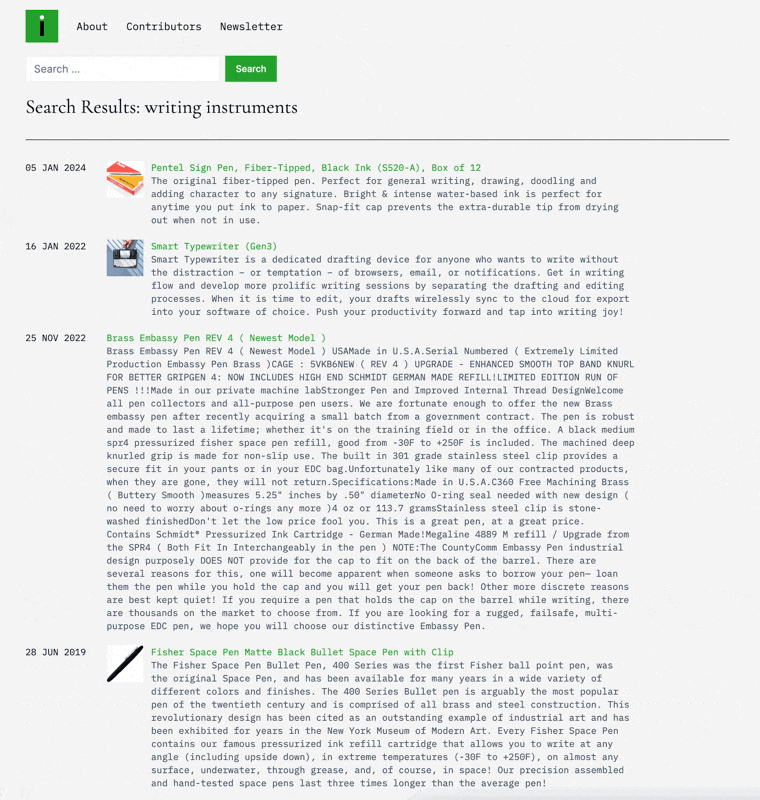
Finally, once everything is in there, I use OpenAI’s embeddings model to generate a vector representation of the product, description, and category, allowing me to have a search engine and make product recommendations.

Of everything you can do with AI, this is one of the most amazing to me. If you need a refresher on embeddings and vector space, I wrote about it last year, but basically, it is a way to capture the AI’s intuitive understanding of some text and use that to chart the relative distance between things as a way to search/recommend. So when you search for funny books, what’s going on behind the scenes is that I’m taking those words (“funny book”) and sending them to OpenAI to get the vector representation for that phrase. From there, I’m taking that representation (which is delivered as 1,536 numbers in an array) and sending it to my vector database (in this case, Upstash Vector) to give me the nearest products to that term (I’ve pre-run all the products through and stored them). To say this was a hard problem before would be an understatement. The fact that I can do this for almost no money (OpenAI charges $0.00002 / 1K tokens, and Upstash Vector is $0.40 / 100k requests) is totally wild to me.
That’s it for now. I hope you enjoyed this, and if it’s generally an area of interest for you, you should try to make it to my NYC event on May 8.
If you have any questions, please be in touch. If you are interested in sponsoring, reach out, and I’ll send you the details (we’ve already got a few sponsors on board).
Thanks for reading,
Noah