

Rethinking AI Analogies // BrXnd Dispatch vol. 43
First talk from my recent BrXnd Marketing X AI Conference on the need to leave our AI aperture open.

You’re getting this email as a subscriber to the BrXnd Dispatch, a (roughly) weekly email at the intersection of brands and AI. Wednesday, May 8, was the second BrXnd NYC Marketing X AI Conference, and it was amazing. If you missed it, all the talks will be going up on YouTube, and I’ll have lots more content coming out soon. The fine folks at Redscout were kind enough to do a quick turnaround writeup the day after the event, so you can check that out for now.
I am just starting to get some videos posted of the event and will be rolling them out in the coming weeks. I thought it might be helpful to start with the talk I gave to open the day and offer some context for why I felt it was important to continue the event in year two. If you just want to watch the talk, you can do so below, but I’ve also included a write-up, lightly edited from my original notes.
One of the things I wondered aloud at last year’s conference was what the best analogy for AI was. I offered a few not particularly notable ideas, including one that suggested AI is a little like IKEA selling you a box of materials that can be anything you ask it to be—able to rearrange and organize itself depending on whether you want a bookshelf, bed, or bench.

Not too long after, I abandoned this particular analogy. First, I didn’t think it was all that good, and second, I came to believe we need fewer boxes around AI, not more of them. This was a big theme for the talk and the day: we need to remove the boxes we’ve prematurely placed around this technology and open the aperture of possibilities. It’s too early to say that there are two, or three, or even ten use cases (despite what the “experts” might say).
Even though I left my Ikea analogy behind, I didn’t abandon the search. One day, while watching YouTube with my daughters, I stumbled on a video about how bikes work. In the video, Dr. Derek Muller, who runs the channel Veritasium, tries out a special kind of bicycle that is designed to illustrate the very strange physics of these familiar machines. The bike has a radio control that allows it to lock out steering to the left or right, on command of someone not riding the bike. The reason behind it is to prove a very counterintuitive point about bicycle riding: you need to steer left to turn right and steer right to turn left.
If you could ride this bicycle, you would find it's impossible to turn left without first steering right, and it's impossible to turn right without first steering left. This seems wrong. I think most people believe you turn a bike simply by pointing the handlebars in the direction you want to go. After all, this is how you drive a car. Point the front wheels any direction you like, and the car just goes that way. But the difference with a bicycle is steering doesn't just affect the direction you're headed, it also affects your balance. Imagine you want to make a right turn, so you steer the handlebars to the right. What you've done is effectively steered the bike out from under you, so now you're leaning to the left. And the ground puts a force on the bike to the left, so the only way not to fall is to steer the bike to the left. … This is something anyone who rides a bike knows intuitively, but not explicitly.
I believe this is an even better analogy for AI than the magical Ikea box. AI is like a bike because the only way to learn about it is to get on and ride. No amount of reading books, listening to lectures (like this), reading LinkedIn posts, or reading AdAge articles is going to show you the way.
But as I dug deeper into the history of the bicycle, I also found a few more interesting layers to the analogy. The real magic of bicycles wasn’t the technology, which, like AI, had already existed for 75 years before the introduction of the safety bicycle in the late 1800s kicked off the “bicycle craze.” No, the impact of these machines was most felt in the second and third-order effects. The Wright brothers famously built their first planes out of their bike shop thanks, partly, to the comfort they had gained using lightweight and high-strength parts in their custom-made cycles.
Bikes are also credited with leading to the car's introduction, as they opened up the realm of the possible.
How the bicycle led directly to the automobile is described by the inventor Hiram P. Maxim, Jr., in Horseless Carriage Days (published in 1937): "The reason why we did not build mechanical road vehicles before this [1890] in my opinion was because the bicycle had not yet come in numbers and had not directed men's minds to the possibilities of independent long-distance travel on the ordinary highway. We thought the railway was good enough. The bicycle created a new demand which was beyond the capacity of the railroad to supply. Then it came about that the bicycle could not satisfy the demand it had created. A mechanically propelled vehicle was wanted instead of a foot-propelled one, and we now know that the automobile was the answer."
Maybe the most unexpected knock-on effect of bicycles was in inspiring Steve Jobs. The quote above is from a Scientific American article Jobs read as a kid that drove him to think of computers as “a bicycle for the mind.” Here’s Jobs describing it:
I remember reading an article when I was about 12 years old, I think it might have been Scientific American, where they measured the efficiency of locomotion for all these species on planet Earth. How many kilocalories did they expend to get from point A to point B? And the Condor won and came in at the top of the list, surpassed everything else, and humans came in about a third of the way down the list, which was not such a great showing for the crown of creation. But somebody there had the imagination to test the efficiency of a human riding a bicycle. A human riding a bicycle blew away the Condor, all the way off the top of the list. And it made a really big impression on me that we humans are tool builders, and that we can fashion tools that amplify these inherent abilities that we have to spectacular magnitudes. And so for me, a computer has always been a bicycle of the mind, something that takes us far beyond our inherent abilities. And I think we're just at the early stages of this tool, very early stages, and we've come only a very short distance, and it's still in its formation, but already we've seen enormous changes. I think that's nothing compared to what's coming in the next hundred years.
Analogies allow us to transfer our understanding from one domain to another: to flexibly adapt our knowledge to new situations. This ability to generalize and make conceptual leaps is a hallmark of human intelligence. In fact, Douglas Hofstadter, author of the Pulitzer Prize-winning book Gödel, Escher, Bach, has argued for decades that analogy-making is at the core of cognition. In Hofstadter's view, seeking an analogy for AI isn't just a communication device but a way of trying to grasp the essence of this complex phenomenon. He has a beautiful illustration of his point by answering why babies don’t remember things and why life seems to be moving faster, which he believes comes down to analogy-making. Essentially, Hofstadter believes that analogies are how we “chunk” the world, allowing us to more easily break the enormity of reality into manageable bits that we can then put inside other bits.
All of this is due to chunking, and I speculate that babies are to life as novice players are to the games they are learning —they simply lack the experience that allows understanding (or even perceiving) of large structures, and so nothing above a rather low level of abstraction gets perceived at all, let alone remembered in later years. As one grows older, however, one’s chunks grow in size and in number, and consequently one automatically starts to perceive and to frame ever larger events and constellations of events; by the time one is nearing one’s teen years, complex fragments from life’s stream are routinely stored as high-level wholes — and chunks just keep on accreting and becoming more numerous as one lives. Events that a baby or young child could not have possibly perceived as such — events that stretch out over many minutes, hours, days, or even weeks — are effortlessly perceived and stored away as single structures with much internal detail (varying amounts of which can be pulled up and contemplated in retrospect, depending on context). Babies do not have large chunks and simply cannot put things together coherently. Claims by some people that they remember complex events from when they were but a few months old (some even claim to remember being born!) strike me as nothing more than highly deluded wishful thinking.
In other words, analogies are our natural way of ordering the world, allowing us to stay adaptable even when faced with totally new information and experiences.
Interestingly, this is also a place where current AI systems fall down. Melanie Mitchell, who was a student of Hofstadter, has a great story in her book Artificial Intelligence: A Guide for Thinking Humans about Google Deepmind’s attempts to build the perfect video game AI. One of the games they trained the system to play was Breakout, the brick-breaking Atari game (which, interestingly enough, Steve Jobs and Steve Wozniak helped design and develop). In less than a day, the AI had become the best Breakout player in the world, demonstrating skill at tunneling up and quickly (and safely) eliminating all the bricks from the top down.
This challenge of overfitting is not unique to game-playing AI. It lurks behind many of the limitations and failures of current AI systems. A facial recognition system that performs flawlessly on the faces it was trained on but failed to recognize those same individuals when they put on a pair of glasses. A language model that can generate fluent and coherent text, but when prompted with a nonsensical or contradictory statement, confidently produces equally nonsensical or contradictory completions. In each case, the AI has mastered the specific patterns in its training data but has not grasped the deeper, more abstract principles that would allow it to generalize beyond that narrow domain.
Overfitting is an analogy itself and a quite useful one, I’d argue. While we can obviously overfit models, as happened with Breakout and frequently happens in finance department spreadsheets around the world, we can also stretch metaphors past their limits. If I were to try to put words to some feelings I’ve been having lately about the state of AI in marketing, I’d say we’ve overfitted the analogies: too narrowly drawing conclusions from not enough data about what these tools can and can’t do.
What I hoped to accomplish with my talk was to step back from the potential overfit and open the aperture again. Marshall McLuhan, one of my favorite thinkers about technology and media, had this wonderful concept of “probes,” which he used to help expand thinking around media and communications.
The medium I employ is the probe, not the package ... that is, I tend to use
phrases, I tend to use observations that tease people, that squeeze them, that
push at them, that disturb them, because I’m really exploring situations, I’m
not trying to deliver some complete set of observations about anything. I’m an
investigator, instead of explaining I explore.
Robert K Logan, a physics professor and McLuhan scholar, said McLuhan “would explore not because he thought it was correct, but because he found it interesting and believed it might lead to new insights. Unlike most academics, McLuhan was more interested in making new discoveries than in always being correct.” That, to me, is a noble aim and something I’d like to try to push for over the next six or seven hours.
To bring things full circle, it strikes me that one use for analogies is as a kind of probe of reality. We take ideas from one realm and try to apply them to another as a way to test an idea’s edges.
That’s what I hope to do with this talk (and essay). I want to probe our understanding of how and where AI can be most useful with ideas and experiences from my last twelve months of building, tinkering, talking, and exploring this amazing technology. These come from my first-hand experience playing, building, and consulting on AI projects over the last twelve months. Like McLuhan, I present them humbly, not as answers, but as questions to help us all explore. They’re structured as Even/Over statements, meaning they’re meant to be read as two positive things where the former is prioritized over the latter: “A good thing even over another good thing.” They’re a favorite strategic tool of mine because they force us to choose, which is the essence of strategy.
Probes
React > Generate
Months ago, I was sitting with a friend of mine who runs an innovation agency, and we were talking about some AI tools we had seen that were specifically focused on generating strategy and insights. Like a lot of AI marketing tools, this sounds like a good problem to solve—who wouldn’t want more insights?
But we both felt a little uneasy about it, not because we were threatened by it, but because neither of us was sure that what was actually needed was more insights. As we dug deeper, what he said was that he had a team full of talented strategists who were quite capable of coming up with insights—in fact, that was what they liked to do best. Their biggest challenge was selling those insights to clients. That’s where he spent most of his time as CEO: helping the team to sell their work.
As I was working on this talk I recorded myself giving it and sent the transcription + prompt to Claude 3 with a request to critique the content. One amazing bit of feedback the model gave me was that this React > Generate section was light on examples and could use something more tangible. I went back and added screenshots from that chat as the perfect illustration.

With all the focus on AI as a tool to generate, whether it was writing, insights, or just about anything else, we were overlooking the possibilities of its role as a reader: offering feedback and helping to refine and clarify existing work.
Systems > Models
A big source of confusion around AI seems to be about where the models end and the software begins. The example I offered earlier about math, for instance, is only true if you are working narrowly with the model. When you’re interacting with Siri, for instance, the model is interpreting your question, but then it will have the computer do the math to make sure it's right. Similarly, most of the major models now have the option to have the model choose “tools” to use in giving you an answer. This is obviously where this technology will go.
One place I’ve seen this be super effective is Retrieval Augmented Generation (RAG). It’s the process of combining the model with some deterministic process to “augment” its output. The simplest version, which I’ve built a few times in a few different circumstances, both for myself and others, is loading up lots of documents and then using the output of those to be able to answer questions. I used this with a friend as part of a strategy project. They had 40 hours of transcripts and were able to put it all into the RAG system and ask questions of the collective (while also still going back to the verbatims).
I’ve also been working on my own personal RAG, with all my documents loaded in, so I can ask questions and get feedback from my own corpus. RAG is a super simple technique available with off-the-shelf tools that makes these models significantly more powerful.
The point is that the model itself is just a piece of a much bigger puzzle.
Extract > Write
One of the first use cases I discovered that truly opened my eyes to the possibilities of AI was turning unstructured data into structured data. Specifically, I realized that if I gave GPT-3 (the most advanced model at the time) a data structure in JSON, it could parse a website and return that data in the structure I requested. Having spent entirely too much time over the years building brittle web scrapers that relied on class names and other structural elements that might change tomorrow, this ability blew my mind.
I used it to build my initial BrXnd Landscape, where I scraped pricing pages to offer a comparison across tools.
And, more recently, I built WITI Recommends, which pulled all the recommendations from five years and 1500 emails and put them into a searchable site. Would this have been possible without AI? Of course. Would it have been feasible without AI and a big budget? Of course not.
This is one of those things I’ve continually come back to as a boon for nearly any project I’m working on. The realm of what’s possible expands immensely when you turn unstructured data into structured data that you can use in deterministic code.
Vibes > Evals
Every time a new model comes out, a bunch of benchmarks come with it. The model companies proudly proclaim that their new AI is smarter than the rest. They can prove it because it did great on the evaluations.

So what, exactly, is the MMLU? Measuring Massive Multitask Language Understanding is an evaluation developed in 2020 that “covers 57 tasks including elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, models must possess extensive world knowledge and problem-solving ability.” It’s a little like an SAT for AI models.

The only problem is that everyone who spends a lot of time with these models knows that performance in these kinds of evaluations doesn’t mean all that much. That’s not to say that they aren’t measuring something important, it’s just that they’re the equivalent of interviewing a creative director by giving them the SAT. That’s why everyone who spends any time with these models relies on the vibes.
Tim Hwang, who I mentioned earlier and will be speaking in about an hour, had a wonderful tweet from a year ago that gets at exactly the problem. (As an aside, if anyone wants to collaborate with Tim and me on an issue of AI Spectator magazine, be in touch.)

This isn’t fundamentally a problem at all, but gets to a deeper point about these models: hallucinations are a feature, not a bug. Their ability to imagine a new world, trained as it is on the one that exists, is the real magic.
An example I showed last year from my brand collabs project was how many sneakers the AI imagined that included a swoosh regardless of the brand requested. In both these cases, the model technically hallucinated by adding a swoosh. But, like the quotes, while they were technically inaccurate, they were perceptually correct. In other words, the mistake the AI was making, in this case Dall-E 2, was not that it imagined some impossible thing, but rather that it drew a connection between Nike and sneakers that is incredibly common amongst the general population. The hallucination wasn’t an act of deceit or even necessarily a mistake, but rather a totally reasonable illustration of American brand associations.

While it’s understandable that we all want to find ways to limit the hallucinations, it will always be easier to lean into them.
Bottom-Up > Top-Down
Speaking of vibes, I had a funny conversation recently with an agency. I was asked to give a talk to the executive team about AI, and they asked me what everyone else was doing. Headlines abound, as do bold proclamations in investor presentations, but on-the-ground work is harder to come by.
One big pattern I’ve witnessed is the AI mandate: CEOs are telling CMOs they need to adopt AI, CMOs are telling their VPs, VPs are telling their agencies, and so on and so forth. I just heard a story last week from someone at a $50 billion company who had recently come out of mandated AI training. Afterward, when she asked how she might actually try some of the tools that were mentioned, she was told that she could join a 1,500-person waiting list for access to ChatGPT.
At the same time, lots of people in the organization are exploring and even succeeding in finding ways to integrate AI into their work. Empowering and featuring those folks is the real key to making this transition happen. Again, because of everything I said at the beginning about the counterintuitive nature of this technology, finding use cases will be much easier organically than through top-down directives.
But none of it matters without access. Find ways to let people play with these things if you want any hope of finding business-driving use cases.
Examples > Prompts
At the beginning of the year I was helping a large company think about prompting. As such, it led me to go back and read a bunch of the latest prompting research. I had looked at it before, but I hadn’t gone particularly deep.
This dive led me to a few interesting conclusions.
First, there are really only three prompting techniques that matter: zero-shot (ask the model a question), few-shot (give the model some example answers along with your question), and chain of thought (give the model some example thought processes and answers along with the questions). Sure, there are some other ways of doing it and some more advanced techniques, but the basic idea is that the more examples you give a model, the better its output (quantitatively measured).
In the chart below, you can see that Medprompt, an advanced prompting strategy developed by researchers at Microsoft and published in December, significantly raised the quality of the output of GPT-4 against other prompting methods (as measured against the model’s ability to answer medical test questions directly). They were able to get the same results as a model specifically designed for medical questions by tuning their prompts with good examples and chain of thought prompts (along with a few other techniques).
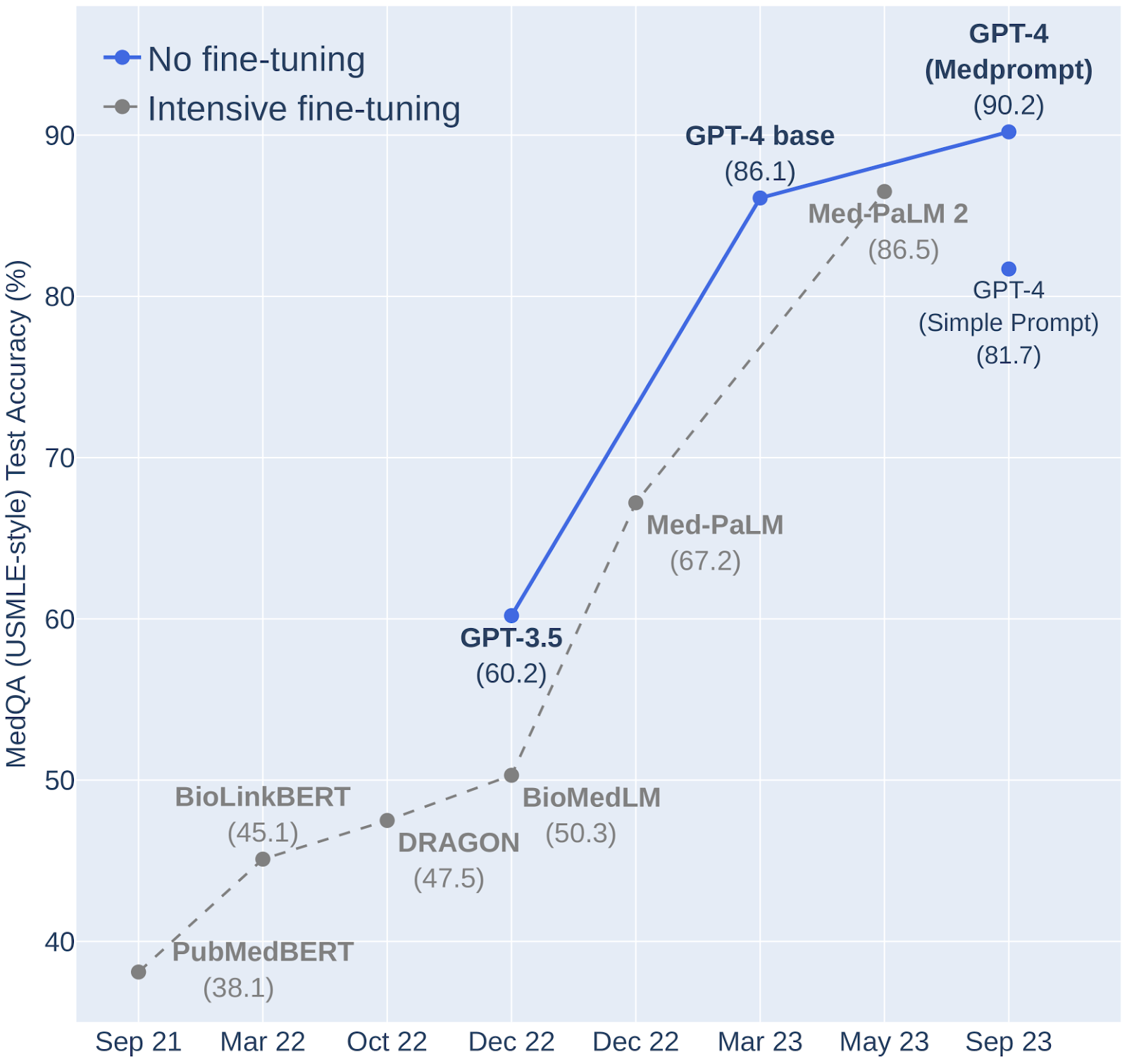
The message was clear to me; the magic of prompting wasn’t in the models. Rather, unlocking the power of the models required human expertise, examples, and experience. Even if you aren’t using AI extensively yet, thinking about building your repository of great examples will be critical to success.
Process > Output
Finally, I want to offer up something I’ve experienced over and over with these tools; their ability to do things we’ve never before experienced with computers has made me more thoughtful about the process I go through to create. It also makes the lines more blurry between the uniquely human steps in the process and those that can be duplicated by machine.
Take the Manifesto Machine. Manifestos themselves are a kind of analogy: a chunk of information that carries a lot of ideas therewithin. Part of what’s fun and interesting about playing with this technology, particularly building things on top of it, is that it forces you to abstract a concept like a manifesto into its parts so that a) you can get them as input from users and b) you can explain them as inputs for the AI.
For the Manifesto Machine, we started simply:
Brand
Category
Start year (slider)
That worked all right, but the AI (GPT-4 Turbo in this case) was a bit too verbose and wrote in full paragraphs instead of the more staccato style normally associated with brand manifestos. So we added a few more options (for both rhythm and length) and continued to tune the prompt.
But then a new issue arose: the model didn't always know enough about the brand. So we needed to feed it some additional information to give it context to work from. To handle that, I wrote a bit of code to grab the top Google results for the brand + category input and return the result titles and descriptions as part of the prompt for the AI. From there, we also added “call to action,” allowing you to specify a specific refrain or CTA, and also a “historical reference” input in case there was a particular event you were hoping to use as your jumping-off point. In the end, here’s how the whole prompt looks:
You are the world\'s best advertising copywriter, and you\'ve been hired to write an anthemic manifesto. Do not make it rhyme or you will be punished. You will be given some criteria to work with:\n- Brand: the name of the brand\n- Product category: the category of product the brand sells\n- Edginess: A 1-5 scale where 1 is incredibly tame, and 5 is the edgiest manifesto the world has ever known.\n- Length: Short = 4 sentences/phrases, Medium = 7 sentences/phrases, Long = 12 sentences/phrases\n- Rhythm: Stacatto = short, impactful sentences, Legato = longer, flowing sentences\n- We Believe: true = structure the middle section with some punchy "we believe" lines, false = ignore "We Believe" instructions\n- Start date: For the start date, choose famous things that happened around that time and use that as a starting point (if the date was 66 million BC, it might be something like "Since the days T-Rex roamed the plains," whereas if it was 1492 it might start with "When Columbus crossed the ocean ..." The start date is not when the company started, but rather the point in time at which the story of the manifest should start from.\n- Additional Context from Search: You will also be given some context from Google results about the brand. Use those to help inform the story.\n\nWrite an epic manifesto that would make David Ogilvy and Jay Chiat proud! Do great work, this is very important to me.\n- Additional Context from User: A few optional fields the user can include to help define things like target audience, call to action, or any historical references they specifically want you to hit on in your manifesto.\n\nExtra Instructions:\n-Do not mention the edginess, it is just an input for you.\n- Do not return Markdown.\n- Manifestos should be written with line breaks between each sentence for dramatic effect. This is how real manifestos are written for brands. Do not return double breaks between paragraphs.\n- Do not rhyme. We write serious manifestos.
This is, in many ways, the most valuable part to me. The technology itself pushes you to reflect on your own processes and consider how they could be improved.
There’s a famous aphorism, often misattributed to McLuhan: “We shape our tools, and thereafter our tools shape us.” That’s what this feels like to me.
Or, put another way, here’s Hofstadter from his masterpiece Gödel, Escher, Bach: an Eternal Golden Braid:
Sometimes it seems as though each new step towards AI, rather than producing something which everyone agrees is real intelligence, merely reveals what real intelligence is not.
That’s it for now. This was a long one. Thanks for reading, subscribing, and supporting. As always, if you have questions or want to chat, please be in touch.
Thanks,
Noah